Как скачать и восстановить сайт из вебархива?
Наткнулся на битую ссылку. Ссылка была на мануал по настройке бэкапов для сайта. Тема интересовала настолько, что полез в archive.org смотреть, что там за мануал такой. Там обнаружил блог человека, который когда-то занимался сайтостроительством, какими-то темами в интернете. Но видимо бросил всё это. Блог существовал до декабря 2013 года, потом еще год висела заглушка. Я возьми да и проверь домен сайта. Он оказался свободным. Дело в том, что меня интересовали подобные сайты давно, я время от времени захожу на telderi и присматриваю себе недорогой сайт IT-тематики для покупки. Пока ничего подходящего по цене/качеству не подобрал.
Зачем мне нужен такой сайт? Я вынашиваю план сделать что-то вроде слияния или поглощения. Соединить такой сайт, с вот этим. Чтобы увеличить на нем трафик и прочие ништяки. Кто-то скажет — а как же диверсификация? Безусловно, диверсификация — дело хорошее. Но тут ещё диверсифицировать пока нечего, нужно сначала что-нибудь развить. И вот, видится мне идея слияния сайтов очень перспективной.
Итак, это всё предыстория. Задумал я найденный сайт восстановить. Оказалось на нём около 300 страниц. Зарегистрировал домен и принялся разыскивать инструмент для выкачивания сайта.
Чем восстановить сайт из веб архива?
Процедура-то нехитрая. Бери и качай. Но дело осложняется тем, что страниц много, и все они будут в виде статических html-файлов. Вручную качать замучаешься. Стал спрашивать у людей, которые таким делом занимались. Люди посоветовали r-tools.org. Он оказался платным. Стал гуглить, поскольку я-то знаю, что это простая процедура, и платить за нее не хотелось, пусть и такую небольшую плату. Решение нашлось очень быстро в виде приложения на ruby. Как я и предполагал, всё очень просто, инструкция прилагается.
Устанавливаем утилиту для восстановления сайтов из archive.org
Недолго думая, устанавливаю всё на сервер и запускаю восстановление.
#устанавливаем руби:
apt-get install ruby
#Ставим сам инструмент:
gem install wayback_machine_downloader
Запускаем выкачивание сайта из веб архива

wayback_machine_downloader http://www.site.ru --timestamp 20131209110704
Здесь в опции timestamp можно указывать отметку снапшота. Поскольку сайт может иметь десятки или сотни снимков в веб-архиве. Я указываю последний, когда сайт был еще жив, логично. Утилита сразу же определяет количество страниц и выводит на консоль выкачиваемые страницы.
Все скачивается и сохраняется, получаем россыпь статических файлов в папке. Создаем у себя папку в нужном месте, и кладем туда выкачанные файлы. Я люблю использовать rsync:
rsync -avh ./websites/www.site.com/ /var/www/site.com/
Остается только создать конфигурацию в nginx, дождаться обновления dns.

Ну а для тех, кто хочет много букв с непонятными командами и скриптами, разобраться и делать самостоятельно — продолжаем.
Создание конфигурации nginx для восстановленного сайта
Я делаю универсальный конфиг, с прицелом на будущее — обработку php. Возможно понадобится, если захочется оживить сайт и доработать фунционал, например формы отправки сообщений, подписки.
А вообще, минимальная конфигурация для статического сайта будет выглядеть примерно так:
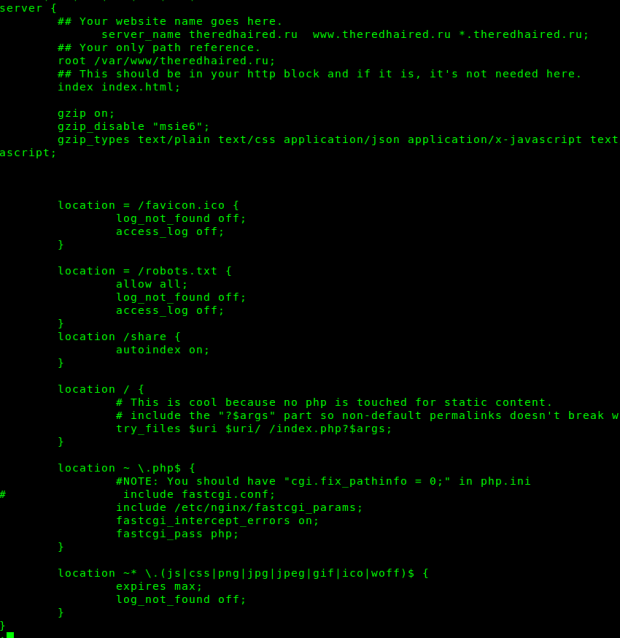
server {
server_name site.ru www.site.ru *.site.ru;
root /var/www/site.ru;
index index.html;
gzip on;
gzip_disable «msie6»;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript;
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location ~* \.(js|css|png|jpg|jpeg|gif|ico|woff)$ {
expires max;
log_not_found off;
}
}
Эта конфигурация заодно включает в себя настройки оптимизации для Google Pagespeed — сжатие и кэширование в браузере.
Перезапускаем вебсервер:
service nginx restart
Как проверить сайт без смены DNS?
В принципе можно ждать обновления dns после регистрации домена. Но хочется поскорее увидеть результат. Да и работу можно сразу начать. Для этого есть нехитрый способ — записать IP сервера для нужного домена в файл hosts, запись такого вида:
10.10.1.1 site.ru
После этого нужный сайт станет открываться исключительно у вас на компьютере.
Вот так. Чувствую себя некромантом :)

Сайт будет показываться ровно так, как видели его пользователи. Все ссылки будут работать, поскольку у вас есть все нужные файлы. Возможно какие-то из них будут битыми, где-то будет не хватать изображений, стилей или чего-нибудь ещё. Но это не суть важно — ведь самое главное для любого сайта — контент. А он, скорее всего, сохранится.
Очистка кода восстановленного сайта
Но это ещё не всё. Хотя можно и оставить в таком виде. Но чтобы добиться лучшего эффекта, есть смысл немного причесать восстановленный сайт. Это вообще самая сложная часть во всей этой затее. Дело в том, что раз сайт будет показываться так, как видели его пользователи, в коде страниц будет куча всевозможного мусора. Это в первую очередь реклама, баннеры и счётчики. Также какие-то элементы, которые на статическом сайте ни к чему. К примеру, ссылка для входа в админку сайта. Формы для отправки комментариев, подписки, какие-нибудь кнопки и другие элементы, доставшиеся в наследство от динамической CMS, на которой сайт работал раньше. В моём случае это был WordPress.
Как удалить фрагменты html кода на множестве статических страниц?
Как же это всё можно убрать? Очень просто. Смотреть в коде — и просто удалять ненужное. Легко сказать. Но страниц у нас несколько сотен. Поэтому тут нужна магия.
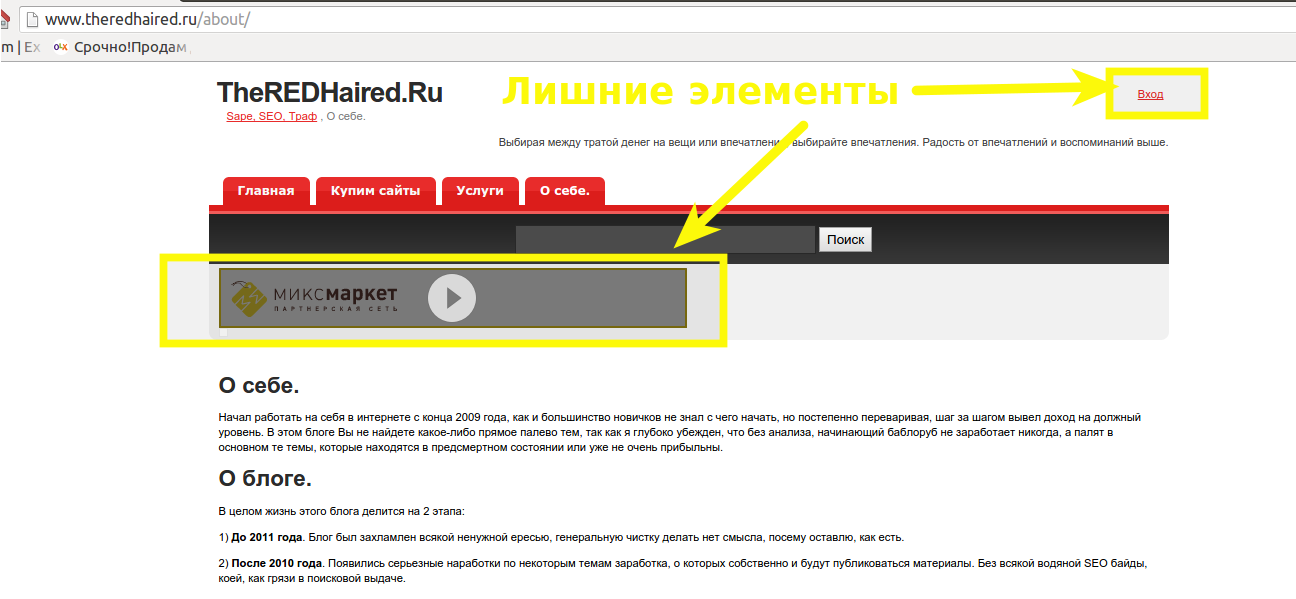
Удаляем сквозные элементы в коде статического сайта
Вот так я убираю ссылку «Вход» на всех html-файлах в указанной папке:
find ./site.ru/ -type f -name '*.html' -exec sed -i 's|<p id="top_info"> <a href="http://www.site.ru/wp-login.php">Вход</a></p>||g'
{} \;
Вот такой конструкцией можно убрать ВСЕ html-теги из файла. Самое простое. У вас тогда получатся текстовые файлы
sed -e 's/<[^>]*>//g' test.html
Нормальный подход, если вы просто качаете контент и потом будете использовать только полезное содержимое для чего-либо другого — для написания новых статей, для дорвеев, или чего-то ещё.
Но мне это не подходит, я хочу сначала воссоздать сайт полностью и посмотреть как он будет оживать и будет ли вообще. Поэтому работа по очистке кода занимает у меня пару часов кропотливой работы. Я открываю страницы сайта, отладчиком смотрю исходный код страниц, нахожу ненужные мне javascript, баннеры, счетчики, формы.
Вот так я убираю счетчик Liveinternet cо всех страниц моего статического сайта:
find site.ru/ -type f -name '*.html' -exec sed -i '/<!--LiveInternet counter-->/,/<!--\/LiveInternet-->/d' {} \;
Вот так убираю подключение рекламного баннера:
find site.ru/ -type f -name '*.html' -exec sed -i 's|<link type="text/css" rel="stylesheet" href="http://mixmarket.biz/uni/partner.css">||g' {
} \;
Несмотря на конструкции, которые несведущему человеку могут показаться страшными — это довольно простые вещи, поскольку в этом счетчике есть уникальные теги-комментарии, по которым мы определяем часть кода для удаления, указав их в качестве паттернов.
В некоторых случаях приходится поломать голову, чтобы вырезать лишнее и не задеть нужное, ведь некоторые элементы могут повторяться на страницах. Например, для удаления счетчика Google Analytics пришлось сочинять вот такое:
Сначала удаляю строку <script type=»text/javascript»> с которой начинается счетчик. Эта команда удаляет строку над паттерном var gaJsHost, поскольку мне нужно удалить её только в этом месте и не трогать нигде больше:
find site.ru/ -type f -name '*.html' -exec sed -i -n '/var gaJsHost/{x;d;};1h;1!{x;p;};${x;p;}' {} \;
Теперь вырезаем остальную часть, которую становится легко идентифицировать по уникальным паттернам в первой и последней строках:
find site.ru/ -type f -name '*.html' -exec sed -i '/var gaJsHost/,/catch(err)/d' {} \;
Аналогичным образом я убираю форму добавления комментариев:
Зачищаю 4 строки с неуникальными закрывающими тегами после строки с уникальным паттерном:
find theredhaired.ru/ -type f -iname '*.html' -exec sed -i '/block_links/{N;N;N;N;s/\n.*//;}' {} \;
А теперь вырезаю довольно большой блок строк на 30, указав уникальные паттерны его первой строки и последней:
find theredhaired.ru/ -type f -iname '*.html' -exec sed -i '/<h2> Подписка/,/block_links/d' {} \;
Вот эти последние пару случаев можно конечно попытаться выпилить с помощью мультистрочных паттернов, но я их так и не осилил, сколько не гуглил. Примеров с multi-line находил много, но они все простые, где нету спецсимоволов, escape-символов (табы, переводы строки).
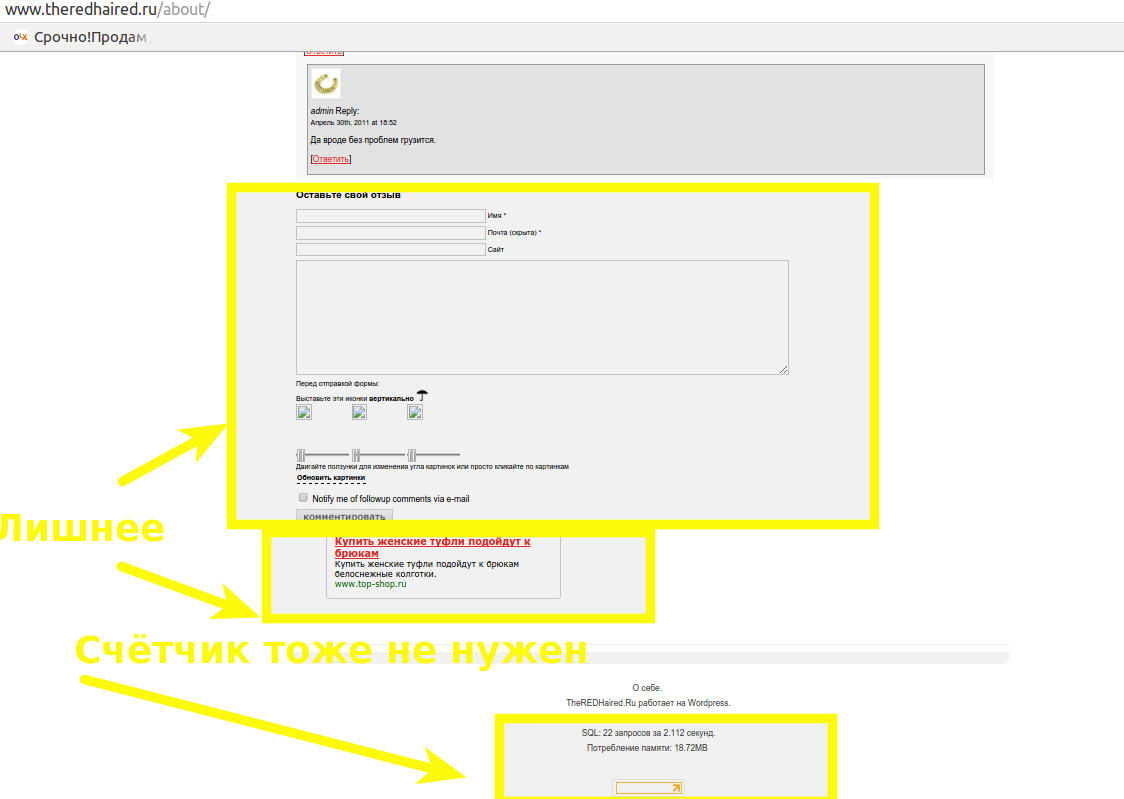
Удаляем счётчики, баннеры и формы с восстановленного сайта
Возможно всю эту очистку будет проще сделать на php или даже perl, для которого обработка текста это предназначение. Но я, к сожалению, оными не владею, поэтому использую bash и sed.
Всё это я проделывал на отдельной копии сайта с кучей итераций, тестов, чтобы всегда была возможность откатить изменения я сохранял копии после каждого значительного изменения, опять же с помощью rsync.
Как массово редактировать тайтлы и другие элементы на статическом сайте?
Поскольку моя задача не просто воскресить сайт, а добиться его индексации, ранжирования в поиске и даже получения трафика из поиска — мне нужно подумать о каком-никаком SEO. Оригинальные тайтлы мне однозначно не подходят, поэтому я хочу их изменить. В наследие от WordPress досталась схема %sitename% » %postname%. Тем более sitename у нас невнятный — сам домен сайта. Самый простой вариант выпилить первую часть тайтла. Но это мне тоже не годится. Поэтому я поменяю эту часть тайтла на хитрый запрос. Вот так я это делаю:
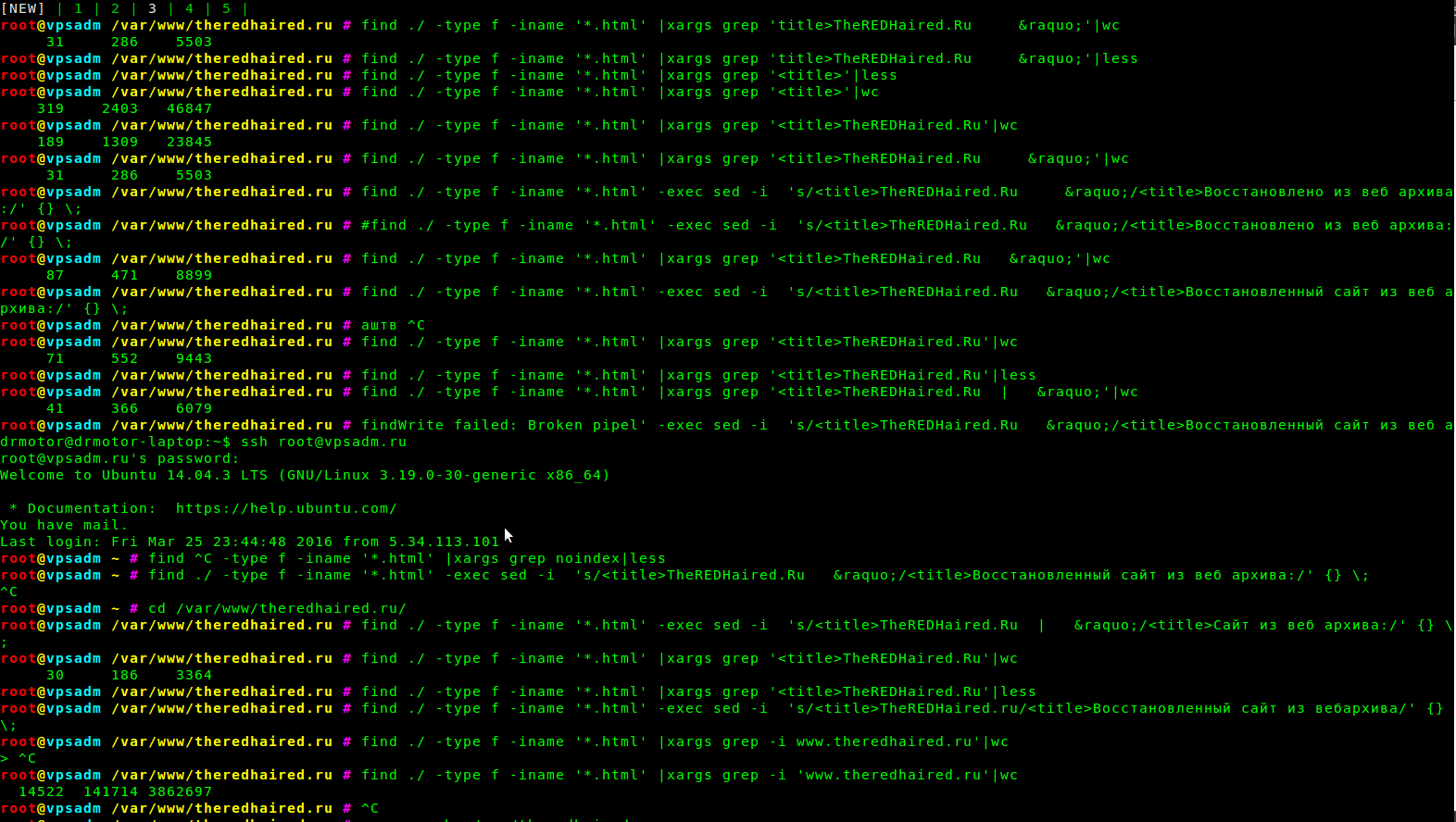
Как видите, множество проверок и итераций. Но в итоге, тайтлы становятся такими, какими нужно. Можно догадаться, что я затеял попытку собирать на этот сайт трафик по запросам о восстановлении сайтов из веб архива. Зачем мне это нужно — я собираюсь оказывать платную услугу по восстановлению таких сайтов. Как видите, в данном случае довольно просто сделать замену. Можно было не заморачиваться несколькими вариантами, а подвести всё под один. Но мне захотелось убрать или поменять лишние символы, а раз уж вариантов оказалось несколько, то я и поменял их на несколько своих. Такое вот SEO.
Теперь я собираюсь добавить Яндекс Метрику во все html-файлы моего сайта. А заодно перевести его со старой схемы www на без www.
Как перевести статический сайт с www на без www?
Это делается простой заменой:
find ./ -type f -iname ‘*.html’ -exec sed -i ‘s/http:\/\/www.site.ru/http:\/\/site.ru/g’ {} \;
После чего на всякий случай в конфигурации nginx вынесем вариант с www в редирект:
server {
server_name www.site.ru;
return 301 $scheme://site.ru$request_uri;
}
Как создать карту сайта sitemap.xml для статического сайта?
Это понадобится, когда мы будем добавлять сайт в поисковые системы. Это очень важно, учитывая что наш сайт восстановленный, на нем возможно отстутствует какая-нибудь навигация, и на какие-то страницы вообще не будет ссылок. Карта сайта этот момент сглаживает — даже если переходом по самому сайту на страницу попасть нельзя — мы указав ее в sitemap.xml позволим её проиндексировать, что потенциально может привести трафик из поиска прямо на страницу.
Генерирую карту с помощью сервиса, который создаёт её из списка страниц. Как получить такой список? Всё оттуда же, из консоли:
find site.ru/ -type f -iname ‘*.html’|grep -v ‘site.ru/go\|wp-login\|wp-admin’|less
На выходе получаю чистенький список страниц и сразу же скармливаю его в сервис. Я тут при генерации списка исключил кое-какой мусор. go — это бывшие внешние ссылки ну и страницы админки, которые у нас всё равно закрыты в robots.txt.
Как установить счётчик на все страницы статического сайта?
Последний штрих. Я ведь собираюсь отслеживать свои успехи. Поэтому мне нужно обязательно добавить какой-нибудь счётчик. Я ставлю на свои сайты обычно и Google аналитику и метрику яндекса. Но работаю больше с метрикой, analytics пользуюсь изредка для специфичных вещей. Здесь же мне счетчик гугла вообще не понадобится, по крайней мере первое время.
Итак, чтобы добавить во все страницы счётчик метрики, я воспользовался способом с выносом кода счётчика в отдельный js-файл. Просто потому, что так будет проще добавить потом код его вызова на все страницы. Создал счётчик, и записал его код в metrika.js
Теперь добавляю строку с его вызовом на все страницы перед закрывающим тегом body:
find site.ru/ -type f -iname ‘*.html’ -exec sed -i ‘/<\/body>/i \
<script type=»text\/javascript» src=»\/metrika.js»><\/script>’ {} \;
Теперь проверяю, везде ли установилось:
find site.ru/ -type f -iname ‘*.html’|xargs grep ‘metrika.js’|wc -l
173
И получаю неприятный сюрприз — установлено не везде. Около сотни страниц упущено. Это могло произойти только в том случае, если в каких то файлах нету тега </body>. Смотрим:
find site.ru/ -type f -iname ‘*.html’|xargs grep -L ‘</body>’|wc -l
119
Как раз в 119 файлах этого тега нету. Это совсем плохо, видимо на каком то из этапов по очистке что-то пошло не так, и был срублен этот тег. Можно конечно выяснить когда это случилось и откатиться до того момента, но это куча работы. Поэтому я просто добавлю в эти файлы недостающие теги, и потом таки добавлю счётчик.
find site.ru/ -type f -iname '*.html'|xargs grep -L '</body>'|xargs sed -i '$ i\
> <\/body><\/html>'
Я делаю это одной строкой, чтобы указать паттерном именно теги в паре. Иначе, если я воспользуюсь для добавления счётчика той же командой, что я уже сделал — то я продублирую вызов счётчика там, где он уже есть. Чтобы этого избежать можно конечно удалить строку там где она есть и потом добавить её снова, но я просто укажу спаренный тег в виде паттерна и добавлю только в те файлы. Вот так:
find site.ru/ -type f -iname '*.html' -exec sed -i '/<\/body><\/html>/i \
> <script type="text\/javascript" src="\/metrika.js"><\/script>' {} \;
Проверяю снова:
find theredhaired.ru/ -type f -iname '*.html'|xargs grep 'metrika.js'|wc -l
266
Ну вот, 266 из 290 это уже лучше :) Там оказалось еще что 30 страниц не попали под какой-то из скриптов из-за кривых имен с вопросительными знаками. Я думаю мне достаточно и тех что есть :)
Что дальше?
Дальше мне пришла в голову мысль заточить имеющуюся на сайте страницу об услугах под предложение восстановления сайтов из веб архива.
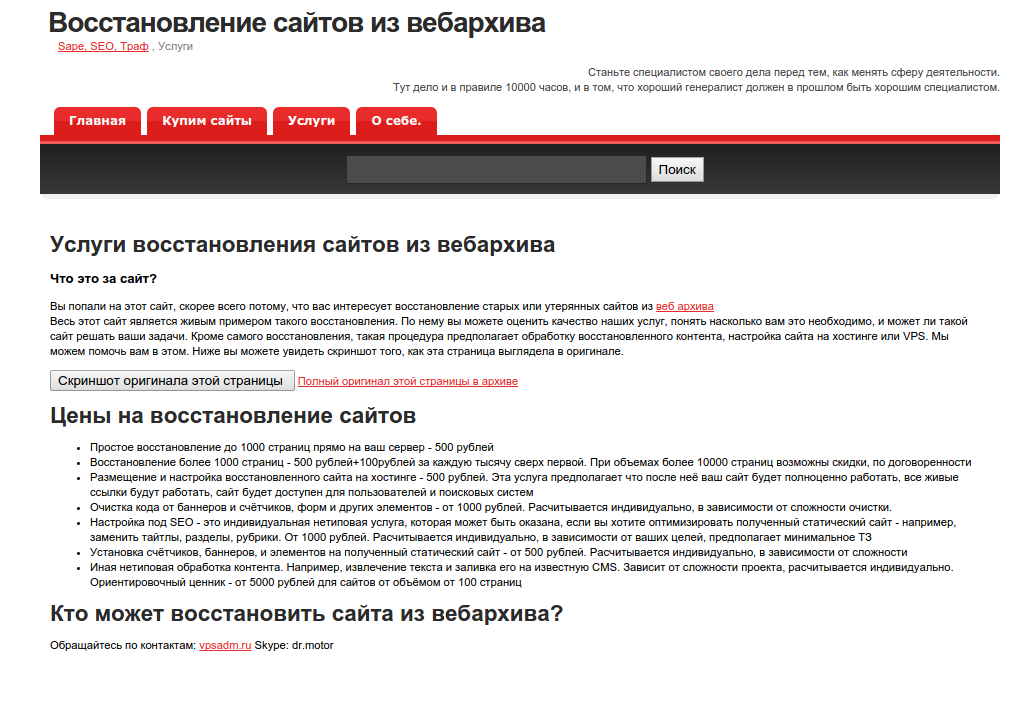
Вот что получилось после очистки и правки страницы под свои нужды
Кроме того, через некоторое время я проведу анализ результатов, которых я достиг с этим сайтом. Трафик, лиды или что-то ещё. Так что, следите за обновлениями на сайте, через 2-6 месяцев вы увидите продолжение истории. Покажу стату, если таковая будет и т. д. Если вы читаете эту статью спустя полгода, а ссылки на продолжение до сих пор нет — напомните мне об этом в комментариях, пожалуйста :)
Если вы прониклись, во всём разобрались и собираетесь делать самостоятельно — низкий вам поклон и уважуха. Мне нравятся люди, которые хотят во всём разобраться и постичь.
Если же вы кроме хаоса в мыслях ничего не испытываете после прочтения, а решить задачу надо, я отношусь со столь же большим уважением к тем, кто умеет находить профессионалов и просто делегировать свои задачи :)
Admin
IT-cпециалист с высшим техническим образованием и 8-летним опытом системного администрирования. Подробней об авторе и контакты. Даю бесплатные консультации по информационным технологиям, работе компьютеров и других устройств, программ, сервисов и сайтов в интернете. Если вы не нашли нужную информацию, то задайте свой вопрос!

Здравствуйте!!!
Комментарий на отдельной страницеесть некоторые проблемы по восстановлению сайтов с веб архива.
дело в том что скаченный сайт , не отображает ни графику ни картинки.
может я изначально все неправильно делаю.
шаг выполнения.
скачал rubyinstaller для виндовс 7
далее в командной строке прописал gem install wayback_machine_downloader
и дальше по схеме и в результате сайт скачивается ,но с проблемами
скажи где я ошибаюсь или оно так и должно быть.
Возможно дело в доноре, которого вы качаете из вебархива. Проверьте есть ли в самом вебархиве нужные изображения. И если их там нет, то значит всё ок. Если они есть в вебархиве и не качаются — это уже другой вопрос, нужно разбираться дальше.
Комментарий на отдельной страницеС донором все нормально картинки есть в архиве ,скажите я правильно установил программу
Комментарий на отдельной страницеу вас написанно что вы установили все на сервер
я же просто скачал программу на комп
Я не знаю как ставить и использовать ruby на Windows, и сходу так не скажу, нужно разбираться. Но если что-нибудь запустилось и даже скачивается, то скорей всего всё правильно установили. Я да, на сервер прямо на хостинг ставил.
Комментарий на отдельной страницеи последний вопрос
Комментарий на отдельной страницепосле скачивания сайта сразу можно загружать на сервер помимо того что у тебя написано в статье, или необходимо редактировать все ссылки на страницы второго и третьего уровня, а также на картинки дело в том что в папке images имеються некоторые картинки в папке css есть стили
Я не редактировал ссылки, у меня сразу всё заработало после выкачивания. Просто выкачал этой утилитой и сделал конфиг для статического сайта.
Комментарий на отдельной страницевсе благодарю за быстрые ответы буду пробовать вроде все получаеться
Комментарий на отдельной страницеЗдравствуйте у меня есть пару вопросов:
1. Скачала Ruby on Rails на какой хостинг заливать.
2. как запустить руби с хостинга , у руби есть своя командная строка?
3.Скрипт wayback_machine_downloader уже есть в руби или его тоже необходимо скачать и заливать на хостинг
Заранее благодарна
Комментарий на отдельной страницеRuby не нужно скачивать, его лучше всего установить из репозиториев. Это возможно только если используете VPS или VDS, а не обычный виртуальный (shared) хостинг. Как ставить — это зависит от используемой операционной системы на вашем VPS. У меня здесь дан пример для deb-систем.
Запуск тоже описан — просто даёте команду wayback_machine_downloader http://site.com. Устанавливается он командой gem install wayback_machine_downloader
Ответы на все ваши вопросы уже есть в этой статье, опишите конкретней что именно непонятно, что не работает.
Комментарий на отдельной страницеУ меня имеется
Комментарий на отдельной странице— ВДС
— centos-6-x86_64-minimal
— панель Веста
Для установки wayback_machine_downloader будет достаточно ruby 1.9.2-p290?
Установку нужно проводить под рутом?
После запуска команды make install в конце установке появляется ошибка, как её можно решить?
Цитирую
» ossl_pkey_ec.c: In function ‘ossl_ec_group_initialize’:
ossl_pkey_ec.c:765: warning: assignment makes pointer from integer without a cast
ossl_pkey_ec.c:819: error: ‘EC_GROUP_new_curve_GF2m’ undeclared (first use in this function)
ossl_pkey_ec.c:819: error: (Each undeclared identifier is reported only once
ossl_pkey_ec.c:819: error: for each function it appears in.)
ossl_pkey_ec.c: In function ‘ossl_ec_group_set_seed’:
ossl_pkey_ec.c:1114: warning: comparison between signed and unsigned integer expressions
make[1]: *** [ossl_pkey_ec.o] Error 1
make[1]: Leaving directory `/usr/src/ruby-1.9.2-p290/ext/openssl’
make: *** [mkmain.sh] Error 1″
Я не знаю зачем make install, у меня установился парсер без компиляции. Просто gem install.
Комментарий на отдельной страницеЕщё раз спасибо за статью.
Команда rsync -avh ./websites/www.site.com/ /var/www/site.com/ выполняет перенос содержимого сайта в папку var/www/site.com/ ?
Скажите, если у меня nginx встроен в Весту, скаченный сайт лежит в отдельной папке домена, то нужно ли выполнять пункт статьи «Создание конфигурации nginx для восстановленного сайта»? Если нужно, то куда вводить описанный вами код?
В разделе «Как удалить фрагменты html кода на множестве статических страниц?» куда вводить команды? В Пати? Будут ли они работать на Centos?
У меня спарсиля сайт без картинок и с плохой кодировкой (символы)?
Если в браузере кодировку поменять, то нормально, но всё равно без картинок.
Прошу извинить, если вопросы глупые. Только начинаю осваивать вопрос.
Комментарий на отдельной страницеrsync -avh делает полную синхронизацию первой указанной папки во вторую.
Если у вас веста — создавайте сайт через весту и всё. Дальше уже смотрите, если не заработает разбирайтесь.
Можно и внести код, конфиг весты лежит обычно в /home/admin/conf/web/nginx.conf. Но тут надо понимать, что у вас он может нужен совсем другой.
По поводу чистки html — да, эти команды надо вводить в консоли. Если вы подключаетесь к ней через Putty, значит в нём. Это стандартные утилиты linux, будут работать в любом дистрибутиве, в том числе и в Centos. Но следует понимать, что команды даны лишь как примеры, они могут у вас и не заработать, если вы не понимаете как использовать эти утилиты.
По поводу проблем с картинками и кодировками — это все решаемо, но не видя сайта сложно что-то говорить. Напишите в скайп, разберёмся.
Комментарий на отдельной страницеПодскажи пожалуйста как восстановить графику и картинки
Если картинок нет на восстановленных страницах это значит их нет в веб архиве. К сожалению их восстановить невозможно. Либо поискать в вебархиве другую версию этой страницы, на которой есть изображения и восстановить конкретно её, указав временную метку.
Комментарий на отдельной страницеА можете скрины или видео добавить? С руби дело не имел и не могу понять что и как делать…
Комментарий на отдельной страницеПосмотрите, страницы сайта могут иметь несколько версий в вебархиве. Проверьте их все, на какой-то страница может быть с картинками. Да тут дело не в руби.
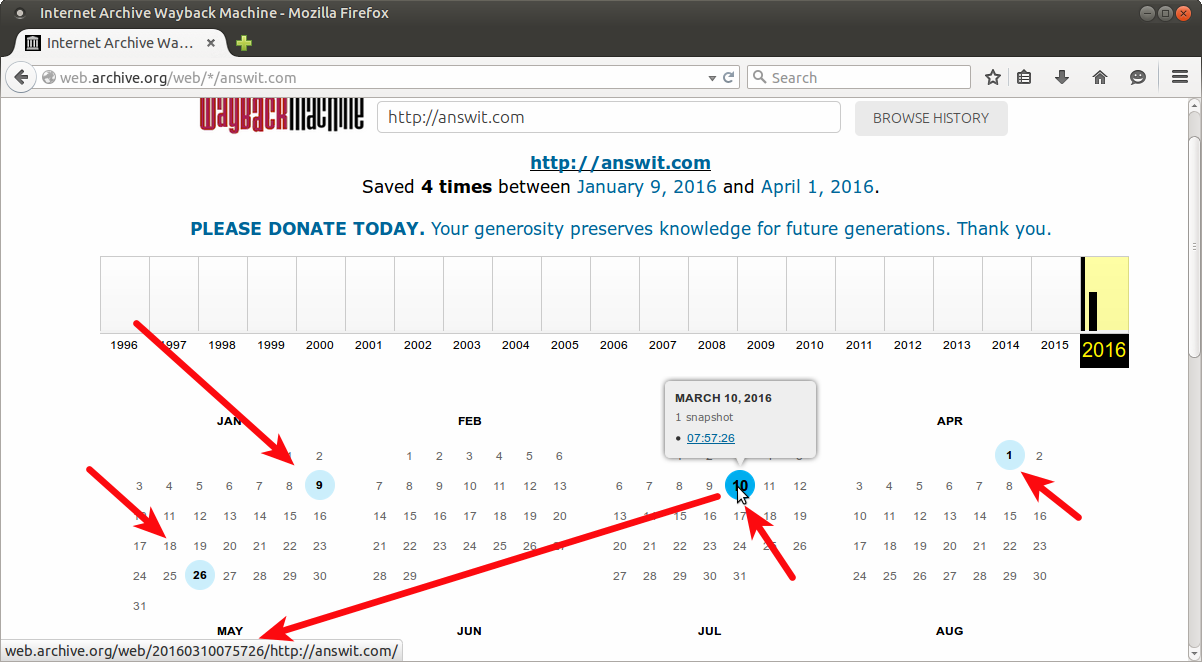
Комментарий на отдельной страницеЕсли такая страница есть, выкачиваете её с параметром timestamp, где указываете метку этой версии.
wayback_machine_downloader http://www.site.ru —timestamp 20160310075726
Огромное спасибо-)) Качнем пару сайтов
Комментарий на отдельной страницеСпасибо большое за статью, все доступно написано.
Комментарий на отдельной страницеПодскажите пожалуйста как можно массово закрыть все внешние ссылки ?
Массово это можно сделать все теми же утилитами обработки текста — sed, grep, awk. В каждом случае это надо тестировать и подбирать свой скрипт. Посмотрите примеры в статье, например как можно удалить участки кода по выбранному шаблону. Точно так же можно удалить и внешние ссылки. Самая важная часть — подобрать шаблон, который позволит сделать то что нужно. Потом, я не понял что значит «закрыть» — это добавить атрибут nofollow или таки удалить, сделать не ссылками?
Комментарий на отдельной страницеЯ просто не смогу написать сам такой скрипт, потому прошу вас что бы вы мне живой пример написали. В разных страницах сайта есть ссылки (открытые) на различные домены. Возможно ли написать скрипт что бы он закрывал ссылки (добавлял атрибут nofollow) на все домены кроме домена моего сайта, заранее спасибо.
Комментарий на отдельной страницеЭто будет довольно сложный скрипт, навскидку так даже не смогу ничего написать. Нужно это писать и отлаживать сразу на файлах сайта.
Комментарий на отдельной страницеБлагодарю автора за интересную инфу по части технических деталей восстановления сайта. Добавлю свои 5 копеек…
При восстановлении сайта из вебархива, будьте готовы, что трафик будет сильно меньше, чем был у ранее работавшего сайта. Причин тут несколько, основная — недоверие поисковиков к восстановленному сайту. Исключение — только совсем ненадолго пропавшие сайты. Т.е. восстановление максимально имеет смысл только для недавно удаленного сайта, когда прежний владелец забыл продлить домен или забил на продление.
Вы писали, что собираетесь переводить сайт с ссылок с www на вариант без него. При этом все входящие на сайт ссылки с других сайтов уйдут в пустоту, кстати вместе с позициями в поиске, которые сильно просядут.
Не понял, зачем восстанавливать сайт в статических страницах. Гораздо выгоднее и удобнее спарсить страницы и запихнуть их в CMS, если она дает возможность сохранить существующую структуру адресов или просто подстроиться под нее. Тогда малейшее изменение на сайте не приведет к тому, что надо ломать голову над очередной версией парсера — заменяльщика какого-нибудь неактуального баннера. :)
Написать скрипт, о котором пишет Максим, абсолютно не сложно, с этим любой нормальный программер справится.
Комментарий на отдельной страницеСайт без www просто потому, что мне так больше нравится. В моем случае никаких там позиций не просядет, потому как их и не было совсем, во-первых. А во-вторых, я же оставляю 301 редирект, поэтому даже если какие-то ссылки с www и ведут на сайт, они будут вести через редирект на ту же страницу без www.
Что касается CMS — это да, удобней конечно, если собираетесь развивать сайт. Но это гораздо сложнее, чем восстановить на статике. На статике все восстанавливается за пару часов. Обычно такие сайты восстанавливают для торговли ссылками через сапу и прочие линкброкеры, а не для развития, поэтому CMS не критична.
Что касается скрипта для замены ссылок — тут все относительно. Говоря о сложности, я имел в виду, что не смогу написать в одну строчку, вроде тех, которые я давал в статье.
Комментарий на отдельной страницеДобрый вечер, никак не могу понять куда сохраняет программа файлы, не подскажете директорию и код как задать правильную директорию?
Комментарий на отдельной страницеПо-умолчанию она создает папку websites/site.ru в текущем каталоге. Т.е. если вы от рута запустите программу на VPS, то файлы сайта окажутся в /root/websites/site.ru
К сожалению у программы нет опции, с помощью которой можно указать папку для сохранения выкачиваемых файлов, по крайней мере документированной.
Поэтому лучше всего предварительно перейти в нужную папку, и запускать выкачивание сайта там. Либо после скачивания перекинуть папку туда, где у вас лежат сайты. Например так:
Комментарий на отдельной страницеmv websites/site.ru /var/www/user/site.ru
а скажите раз сайты выкачиваются статические, то как вставить код сапы и что прописать в .htaccess
Комментарий на отдельной страницедело в том что хостинг поддерживает рхр
может ты пробовал сапу на скаченных сайтах
заранее блогодарен (по фтп не вариант)
Код сапы вставляется примерно так же, как счетчики в примерах в этой статье.
Комментарий на отдельной страницеДа, у меня есть такой статический восстановленный из вебархива сайт, который добавлен в сапу. Код добавлял именно таким способом.
Артём, спасибо за схему скачивания, очень помогла и сэкономила мне около 10000 рублей.
Комментарий на отдельной страницеУ меня вопрос: скачал по вашей схеме сайты, но дальше 1 переходы с центральной страницы выбивает ошибку, хотя все нужные файлы есть. Подскажите что нужно сделать. Я скачивал их не для выкладывания на хостинг, а что бы можно было что-нибудь почитать когда интернета нет.
Пардон, вы к кому обращаетесь? Если ко мне, то я Александр, а не Артем :)
Комментарий на отдельной страницеА по поводу ошибки — не знаю почему у вас она возникает. Программа выкачивает и все ссылки заменяет корректно. Для просмотра оффлайн возможно надо выкачивать чем-то типа teleport pro
Простите Александр, файлы скачаны все, просто система видит файлы сайта как отдельные страницы, а не как целый сайт, teleport pro я пытался использовать, но не получилось скачать им с вебархива. скачивает 1 страницу и всё.
Комментарий на отдельной страницеМожет вы знаете как для системы их скрепить в один сайт?
Комментарий на отдельной страницеТакой сайт нормально работает на хостинге. Значит, можно попробовать установить вебсервер на компьютер и обращаться к нему как к сайту на localhost. Попробуйте поставить на компьютер что-то вроде WAMP или denwer, и залить сайт на локальный хостинг. Еще возможно у вас просто ссылки ведут на какие-то сторонние сайты, а не на нем самом. Не видя сайта сложно что-то посоветовать.
Комментарий на отдельной страницеАлександр, у меня ещё один вопрос появился, скажите пожалуйста, если например для просмотра сайта нужно было регистрироваться, можно ли будет просматривать файлы с него без авторизации после скачивания его копии с вебархива или нет?
Комментарий на отдельной страницеНет, такие страницы просматривать не получится. Ибо, скорее всего, если пользователю для доступа требуется регистрация, то роботы и парсеры тоже не смогут получить доступ к таким страницам. Соответственно, они не попадут в вебархив.
Комментарий на отдельной страницеАлександр, я имел ввиду такую ситуацию: есть сайт, на нём много файлов, большинство можно посмотреть и так, а для некоторых требуется статус VIP.
Комментарий на отдельной страницеНикак не посмотреть. У вас все файлы — статика. Та часть, которая «под статусом VIP» ее нет в вебархиве, не закэшировалось.
Комментарий на отдельной страницеЯ установил Wamp Server, большинство скачанных сайтов получилось просмотреть, но некоторые отказывается открывать, как пользоваться Denver я так и не понял, можете что-нибудь подсказать?
Комментарий на отдельной страницеЕсли через wamp открывается, то все ок. Денвер нет смысла использовать, это один и тот же инструмент.
Комментарий на отдельной страницеЗдравствуйте, помогите достать сайт из веб-архива, если предложение о 500 руб всё еще в силе.
Комментарий на отдельной страницеДа, всё в силе, разумеется. Обращайтесь по контактам на vpsadm.ru или делайте заказ на kwork.
Комментарий на отдельной страницеЗдравствуйте! Установил эмулятор на виду, настроил скрипт, только вот не могу найти куда сохраняется скаченный сайт.
Комментарий на отдельной страницеСайт сохраняется в текущую папку. В ту, где вы находитесь, когда запускаете парсер.
Комментарий на отдельной страницеДомен 3го уровня реально так восстановить? Ибо на известном сервисе такой возможности нет (((
Комментарий на отдельной страницеДумаю возможно, если он есть в самом вебархиве. Домен третьего уровня при восстановлении и сохранении сайтов ничем не отличается от второго, или даже пятого-десятого уровня.
Комментарий на отдельной страницеПроблема с программой Wamp Server, открывает не все сайты из тех что скачаны на ноутбук с вебархива, а те что открывает не показывает без подключённого интернета, как можно просмотреть эти сайты без подключения интернета.
Комментарий на отдельной страницеПросто я их скачал чтобы можно было посмотреть например когда поехал на природу или интернета нет, трафик закончился и тд, а тут такой облом
Возможно (и даже скорее всего), вы неправильно что-то настроили. Либо те страницы, которые вы пытаетесь открыть действительно не скачались из вебархива, и их нет на локальном вебсервере. Так вслепую что-то сказать сложно. А еще, возможно вам следует прописать в файл hosts запись для нужного сайта, ведущую на адрес 127.0.0.1, чтобы открытие сайта происходило именно с этого локального компьютера.
Комментарий на отдельной страницеА можете пожалуйста более подробно рассказать, что изменить в hosts и настройках wamp server
Комментарий на отдельной страницеМожете пожалуйста подробнее рассказать как сделать чтобы wampserver показывал сайты с localhost, а не из интернета
Комментарий на отдельной страницеWamp всегда должен показывать сайты с локалхоста. Но ваш браузер будет искать их в интернете, если не прописать их в hosts. Нужно сопоставить ваши домены с адресом 127.0.0.1
Комментарий на отдельной страницепросто я скачал некоторые сайты которые остались только в вебархиве
Комментарий на отдельной страницевместе с теми которые есть в интернете
Комментарий на отдельной страницеподскажите пожалуйста как конкретно их нужно прописывать — указывать каталог куда я их сохранил? или как?
Комментарий на отдельной страницея просто раньше с вебархива ничего не скачивал, это мой первый опыт.
Нашёл инструкцию как прописать их в файле hosts. Прописал, но вместо того чтобы открыть эти сайты wampserver открывает свою домашнюю страницу, подскажите пожалуйста как их правильно прописать в hosts чтобы можно было смотреть в браузере без интернета.
Комментарий на отдельной страницеНу настройка wamp это отдельная тема, вам нужно поискать мануалы в интернете. В общем и целом это не отличается от любого другого вебсервера. Для того чтобы открывать сайт с локалхоста, нужно в hosts сопоставить айпи 127.0.0.1 c его именем. Т.е нужно добавлять такую запись:
Комментарий на отдельной страницеЯ добавил такую строку, но по всем запросам к скачаным сайтам открывает домашнюю страницу wampserver.
Комментарий на отдельной страницеНу значит что-то не так в нем настроено. http://ruseller.com/lessons.php?rub=28&id=950 — вот здесь описано как настраивать сайты на нем. И про файл hosts даже описано.
Комментарий на отдельной страницеСпасибо за ссылку, ушло некоторое время, но сделал как там указано, теперь выдаёт вот такую ошибку: Forbidden
You don’t have permission to access / on this server.
Apache/2.4.9 (Win64) PHP/5.5.12 Server at http://www.site.ru Port 80.
Комментарий на отдельной страницеМожете пожалуйста подсказать, что теперь делать?
Forbidden означает что доступ запрещен, нет прав к файлам или папкам. Попробуйте перенести их в папку, куда вебсервер будет иметь доступ, либо разрешить доступ для текущих файлов.
Комментарий на отдельной страницеА можно получить подсказку как решить эту проблему?
Комментарий на отдельной страницеЯ же дал:
Комментарий на отдельной страницеЗдравствуйте, нужно ваша помощь по восстановлению нашего сайта, так получилось что не уследили и сайт потерялся, не осталось копии на хостинге, мы проверили веб архиве он там есть, но прочитав вашу статью хотим обратиться к вашим платным услугам. Сможете помочь?
Да, конечно, можем восстановить сайт. Написал вам в почту. А можно так же обращаться по контактам на сайте http://vpsadm.ru
Комментарий на отдельной страницеЗдравствуйте Александр
Возникла такая проблема
при вводе команды
все скачивается замечательно.
но при вводе с временными данными wayback_machine_downloader
возникает такая ошибка
/var/lib/gems/2.1.0/gems/wayback_machine_downloader-1.1.2/bin/wayback_machine_do wnloader:56:in `': invalid option: --timestamp (OptionParser::In validOption) from /usr/local/bin/wayback_machine_downloader:23:in `load' from /usr/local/bin/wayback_machine_downloader:23:in `'пробовал с многими сайтами везде так
Комментарий на отдельной страницеПопробуйте указать опцию в краткой нотации:
Или взять значение timestamp в кавычки, одинарные или двойные.
Комментарий на отдельной страницеЗдравствуйте, возникла такая проблемка
руби я установил на хостинг при помощи Putti
кодом
но при установке самой машины кодом gem install wayback_machine_downloader
возникает такая ошибка
Loading command: install (LoadError) /usr/lib/x86_64-linux-gnu/ruby/2.1.0/openssl.so: symbol SSLv2_method, version OPENSSL_1.0.0 not defined in file libssl.so.1.0.0 with link time reference - /usr/lib/x86_64-linux-gnu/ruby/2.1.0/openssl.so ERROR: While executing gem ... (NoMethodError) undefined method `invoke_with_build_args' for nil:NilClassКомментарий на отдельной страницеПопробуйте установить пакет libssl-dev, поскольку он необходим для работы в данном случае:
После чего запустите gem install повторно.
Комментарий на отдельной страницеЗдравствуйте, Артем. По случаю купили освобождающийся домен. Перед покупкой проверили, сохранились ли какие то файлы в Вебархиве. Нашли больше 1000 страниц. Однако на следующий день после покупки, получить доступ к ним не удалось из-за robots.txt. Откуда он появился у «мертвого» сайта, если за день до покупки проблем со скачиванием не было?
Комментарий на отдельной страницеЕсли покупаете дроп у регру например, они автоматически линкуют домен на свою заглушку, в которой настроен robots.txt с Disallow * . Возможно другие регистраторы поступают точно так же. Вам нужно направить домен на свой сервер или хостинг, где отредактировать robots.txt. После этого вебархив станет показывать доступные страницы.
Комментарий на отдельной страницеps: не Артём, а Александр ;)
Добрый день.
Комментарий на отдельной страницеВот сижу ищу возможность восстановления сайта и наткнулась на ваши коментарии. Может быть Вы поможете восстановить сайт который удалили с хостинга, нет бекапов тоже.
Только статический HTML, js и css. Посмотрите свой сайт вот здесь http://archive.org/web/. Если там есть какие-то страницы вашего сайта, то их можно оттуда извлечь, но сайт будет статическим — без админки, формы отправки сообщений и комментариев работать не будут. Другими словами — если вам в первую очередь нужен контент — то его можно восстановить из вебархива. Можно и распарсить потом этот контент для импорта в какую-нибудь CMS.
Комментарий на отдельной страницеКак раз три дня намучавшись потыкалась на http://archive.org/web/. и нашла 3 картинки нашего сайта 2 наружные и 1 из админки, но какие-то не полные, и года разные и контент старый …………но все-равно надеюсь что есть выход.
Комментарий на отдельной страницеА что это не знаю -статический HTML, js и css
Конечно с хостингом бы решит, но они всячески отказываются.
А сообщать название сайт всем подряд доброжелателям тоже не хочется…..так, как наткнулась на площадку где идет продажа удаленных сайтов с хостинга…..
Что можно еще предпринять?
Восстановить можно только то, что вы видите в вебархиве и ничего больше. К сожалению ничего тут придумать нельзя. Чтобы ваш домен не забрали те, кто охотится за дропами — вам нужно его просто оплатить, чтобы он был под вашим контролем, и он уже никуда не денется.
Комментарий на отдельной страницеПриветствую, Александр. Хочу заказать Вам восстановление сайта из архива, он там есть. Нужно будет убрать старые контакты, админку, счётчики. Поставить метрику и сделать блоки для Google AdSense. Возьмётесь? Цена?
Комментарий на отдельной страницеИ сразу хочу задать вопрос по безопасности такого восстановленного сайта.
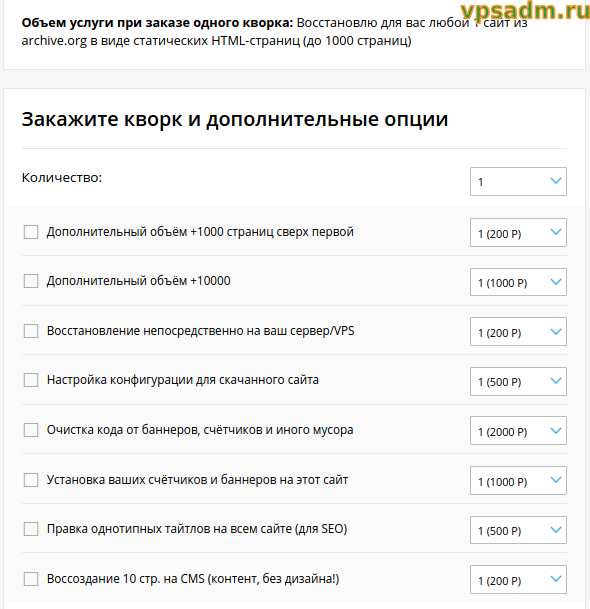
Здравствуйте, Пётр. По таким вопросам лучше обращаться по контактам на http://vpsadm.ru — почта help@vpsadm.ru, skype — dr.motor, whatsapp/telegram — +77078585837. Это и оперативней и проще обсудить. Мои цены на восстановление сайтов и сопутствующие услуги по чистке и доработки таких сайтов сейчас вот такие:
А вот что интересует в плане безопасности — расскажите подробней пожалуйста, я не понимаю вопроса. Комментарий на отдельной странице
Вам пишет Петр по восстановлению, если это реально, то и в очереди по восстановлению сайта.
Комментарий на отдельной страницеПардон, про Петра и очередь не понял вас. Что вы имеете в виду?
Комментарий на отдельной страницеЗдравствуйте, у меня вопрос, есть ли разница в результатах скачивания между системами linux и windows и если есть, то можете подсказать инструкцию и утилиту на linux backtrack.
Комментарий на отдельной страницеТакой разницы быть не должно. Инструкции в этой статье подходят для любого Linux. Как устанавливать софт в Backtrack я не знаю. Что касается Windows — наверное будет точно так же, ибо утилита, которая тут описана работает одинаково в любой ОС, главное чтобы для нее был установлен интерпретатор ruby.
Комментарий на отдельной страницеАлександр, подскажите, установил руби на вин7, руби стал, работает при попытке gem install wayback_machine_downloader выдает
Комментарий на отдельной страницеERROR : Coould not find a valid gem ‘wayback_machine_downloader’
что я не правильно делаю?
Честно говоря, я не пытался устанавливать всё это на windows, поэтому не смогу точно сказать в чем проблема. А другие gem получается установить у вас? Попробуйте. Возможно дело в доступе к репозиториям, или что-то такое.
Вот здесь еще люди пишут какие могут быть проблемы http://stackoverflow.com/questions/9962051/could-not-find-a-valid-gem-in-any-repository-rubygame-and-others
http://stackoverflow.com/questions/40285447/windows-10-64-bit-error-could-not-find-a-valid-gem-compass-0-here-is-w
Предлагают установить сертификаты. В linux у меня ни разу не было проблем с установкой утилиты.
Комментарий на отдельной страницеСпасибо, разобрался.
Комментарий на отдельной страницевсе установилось и работает.
единственное — wayback_machine_downloader http://www.site.ru —timestamp 20131209110704 не хочет качать по заданному timestamp
если убираю эту часть, остается только wayback_machine_downloader http://www.site.ru то сайт выкачивается.
Ну тут нужно смотреть какие ошибки выдаются при попытке использовать эту опцию. И уже по ним ориентироваться.
Комментарий на отдельной страницеПодскажите, такая же проблема Coould not find a valid gem ‘wayback_machine_downloader’ как удалось решить на вин7?
Комментарий на отдельной страницеДобрый день. Подскажите пожалуйста, заинтересовал один сайт, он просрочен на один день(рег.ру). В вебархиве его не видно, можно как нибудь узнать, есть он там или его там никогда не было? В каталоге дмоз он есть.
Комментарий на отдельной страницеЗависит от ошибки, которую выдает вебархив. Иногда бывает что архив не показывает из-за того что включен запрет в файле robots.txt на сайте. Если этот запрет убрать, через некоторое время вебархив откроет содержимое. Ну а если дело не в этом, то значит просто его там вообще нет. Так тоже бывает.
Комментарий на отдельной страницеЗдравствуйте. Подскажите, после скачивания сайта ко всем сссылка добавляется символ /. Т.е. например, в самом сайте есть ссылка site.ru/home, но при клие на ссылку идет редирект на site.ru/home/. Можно символ / как-то убрать? Спасибо.
Комментарий на отдельной страницеЭто происходит потому, что такой урл был на исходном сайте. Страницы получаются в виде папок с индексным файлом index.html . Довольно сложно переделать урлы на такие как вы хотите. По крайней мере я не знаю простого способа. А чем вам мешают эти слеши?
Комментарий на отдельной страницеКак лам дроп поживает из вебархива?
Комментарий на отдельной страницеЕще для восстановления сайта из веб архива можно воспользоваться этим сервисом — ru.archivarix.com — будет гораздо быстрее и проще.
Комментарий на отдельной страницеИнтересный сервис, спасибо. Долго думал а не сделать ли что-то подобное самому. Ну в итоге пока раздумывал — уже реализовали другие.
Комментарий на отдельной страницеВ вебархиве официально объявили о закрытии сервиса, как альтернативу можно использовать http://Site-History.ru правда здесь только скриншоты, но они полноформатны и датированы.
Комментарий на отдельной страницеЯ думаю об официальном закрытии это чушь) по крайней мере есть смысл оставить пруф на такое официальное заявление, если уж сообщаете нам об этом. А сервис глянем, спасибо. Возможно окажется полезен.
Комментарий на отдельной страницеЗдравствуйте, что то у меня не получается с кодировкой, скачал все нормально, когда открываю для редактирования каша полная он не понял русский текст ааОббаАаЛ ааДаОбаОаВбб баЕаЛаОаВаЕаКаА — Atom — вот такая вот штука, не подскажите как поступить?
Комментарий на отдельной страницеНужно смотреть в коде страниц какая указана кодировка. Для этого нужно смотреть код страниц — там указан обычно метатегом:
У вас может быть не utf-8, а какая-то другая кодировка — windows-1251 или koi-8, например.
Комментарий на отдельной страницеЗатем, настроить для сайта кодировку на уровне вебсервера в файле .htaccess, либо в конфигурации виртуалхоста сайта.
Кроме того, есть ещё вариант сконвертировать страницы в кодировку, подходящую для вашего сервера или хостинга, но это более сложный вариант. Иногда приходится прибегать и к этому, если не удаётся решить простой настройкой.
Спасибо за развернутый ответ, именно так и получилось. Вот собралось несколько вопросов некоторые не по теме. Есть сайты которые не хотят качаться вот с такой ошибкой
Комментарий на отдельной страницеC:/Ruby23-x64/lib/ruby/2.3.0/open-uri.rb:359:in `open_http’: 403 Forbidden (OpenURI::HTTPError)
Пробовал по всякому и не хочет скачиваться.
Еще вопрос по поводу времени, т.е. если не указывать timestamp то он должен скачать его полностью как я понял? в принципе получилось так только на одном сайте остальные удалось добиться только после установки времени.
Ну и почти самый главный вопрос, не особо по теме, как определить стоит ли покупать сайт, точнее доменное имя, много всего разного написано в интернете, но интересно ваше мнение, вот собственно посещалка порядка 7000 тыс человек за мес, это удалось найти в статистике, это мало или много? Планируется для заработка с показа рекламы.
Ну и еще если к примеру сайт скачан то возможно ли отдельно у вас заказать очистку, а лучше перевод на CMS и т.п. Заранее благодарю за ответы.
С ошибкой 403 начал сталкиваться и сам недавно. Это похоже на какие-то ошибки — то ли внутри вебархива, то ли на скачиваемом сайте. Я не нашел пока объяснения и решения этому, просто не могу восстанавливать такие сайты, вот и всё.
Если не указывать timestamp — верно, будет выкачан весь сайт, всё что есть в наличи — последние версии каждой страницы. Просто часто бывает, что последние версии страниц на многих сайтах — заглушки хостера или регистратора, страницы ошибок. и т д.
А вот по поводу как определять — тут я не подскажу. Анализируйте — индекс, ссылки, историю домена. Посещаемость 7тыс. в сутки это немало. Хотя зависит от тематики. Ну и конечно нет никакой гарантии что после восстановления будут все те же 7к в сутки.
Очистку заказать можно, но смотря чего. Перенос на CMS пока нет, не занимаюсь.
Комментарий на отдельной страницеЭто уже кое-что. Имея на руках такую информацию, можно оценить трудозатраты при ручном восстановлении обнаруженных в архиве страниц сайта или… Или попытаться найти способ роботизировать этот процесс.
Комментарий на отдельной страницеТолково поработали, Александр! Для справки. Возможности поиска и замены кусков кода есть в поиске-замене Dreamweaver. Там делается очень просто. Иногда этих возможностей не хватает и требуются возможности регулярных выражений. Согласно справке они есть в Дримвьювере. Но я не справился. Какие-то выражения он понимает, какие-то нет.
Кроме того, Дримвьювер строго следит за перелинковкой. Если меняешь имя картинки или страницы или перемещаешь файл в другое место, то он сам просматривает все остальные страницы и производит нужные исправления ссылок. Только нужно, чтобы адресация было относительной, а не абсолютной.
Я пользуюсь Дримвьювером 8.02 десять лет. Более старшие версии не хочу. Сменился владелец, начал менять программу…. Я вообще не представляю, как можно работать с сайтами в несколько десятков страниц без Дримвьювера. Очень рекомендую потратить время на изучение для сбережения того же времени.
Комментарий на отдельной страницеБлагодарю вас , отличный материал точно!
Комментарий на отдельной страницеСпасибо огромное!!!Ценнейший материал.
Комментарий на отдельной страницеДобрый день, с ошибкой 403 удалось что-то выяснить?
Комментарий на отдельной страницеПриветствую. Чаще всего возникает когда на домене стоит robots.txt с запретом доступа для роботов. Пока стоит запрет — вебархив не отдаст содержимое даже если у него что-то есть. Открываете, через какое-то время вебархив начнет отдавать данные.
Комментарий на отдельной страницеВы до сих пор занимаетесь восстановлением сайтов из вебархива?
Комментарий на отдельной страницеДа, занимаюсь. Обращайтесь по контактам на vpsadm.ru
Комментарий на отдельной страницеКак можно удалить битые ссылки с сайта? У донора не все страницы были в веб архиве. Сайт залил в VSC, может там как то можно сделать.
Комментарий на отдельной страницеНе знаю что такое VSC. Но можно их выпилить с помощью регулярных выражений.
Комментарий на отдельной страницеСайт выкачанный с помощью телепортпро поднимаете на wp?
Комментарий на отдельной страницеНет, я не занимаюсь сейчас заливкой восстановленных сайтов на wp.
Комментарий на отдельной страницеДобрый день, спасибо за статью!! Очень полезный материал. Получилось выкачать 400 файлов. Сайт был на wp, все файлы скачались, вот только каждый файл в отдельной папке (папка называется как должен называться файл) и с именем index. Подскажите, можно автоматизировать процесс извлечения всех файлов из папок, чтобы не поднимать его на WP, а просто сделать статический HTML? Спасибо!
Комментарий на отдельной страницеА зачем вам извлекать все эти файлы из папок? Для того чтобы получился статический сайт — просто так и залейте как есть на хостинг, оно будет работать нормально. index файл нужен для всех урлов, которые не на html или php заканчиваются, они вытягиваются как папка с файлом index.html. Веб-сервер такой вариант наиболее корректно обработает без каких-либо дополнительных действий.
Комментарий на отдельной страницеК примеру, в формате Веб Архива 20170501140502 или в коротком формате 201705 (означает по май 2017). Если не заполнено, то получаем самый свежий доступный контент.
Комментарий на отдельной страницеЗдравствуйте, скажите я на виндоус установил ruby, вроде процесс запускается и файлы скачиваются. Но я не пойму куда они скачиваются на компе… В какую папку уходят?
Комментарий на отдельной страницев текущей папке, из которой запускаете процесс, должна создаваться папка websites, там будут создаваться папки с именем домена в названии. Но так ли это работает в windows — я не знаю.
Комментарий на отдельной страницеТема с восстановлением довольно актуальная. Недавно столкнулся, нужно было найти инструмент для восстановления. На текущий момент считаю лучшими платными сервисами архивар Archivarix.com и mydrop.io.
Если самому то https://github.com/hartator/wayback-machine-downloader
Кому интересно свёл плюсы/минусы в статье https://thisis-blog.ru/chem-vosstanavlivat-sajty-iz-veb-arxiva/
Комментарий на отдельной страницеСпасибо чел
Комментарий на отдельной страницеУстановил Ubuntu на VirtualBox, затем установил Ruby, далее установил wayback_machine_downloader. Проверил командой gem list. Все в порядке. Пишу в терминале wayback_machine_downloader http:// 43rd.ru. Получаю ошибку «command not found». В чем может быть причина?
Комментарий на отдельной страницеВ том, что вы пишете downloadER, а нужно wayback_machine_download
Комментарий на отдельной страницеСкачал сайт с веб архива ,открывается только главная , а остальные странички не открываются , какая то заморочка с ссылками ,как исправить подскажите пожалуйста
Комментарий на отдельной странице